AI has become one of the main forces shaping both modern software development and everyday life. For individual developers, having access to a dedicated AI server can make experimentation, training, and deployment far more practical. The problem is cost: high-performance GPU cloud servers often land in a price range that many solo builders simply cannot justify.
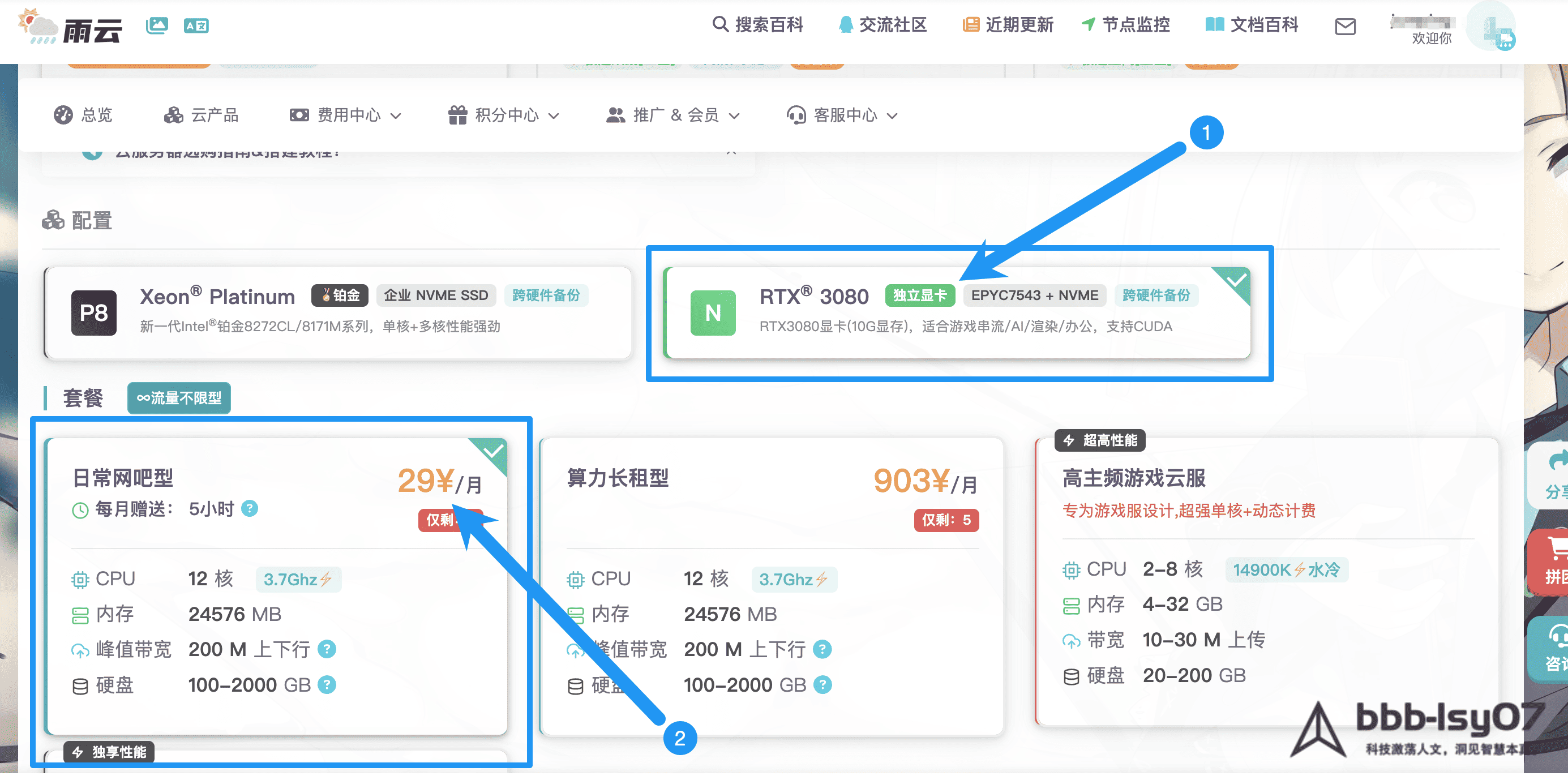
That is what makes low-cost GPU instances so interesting. The configuration tested here is Yuyun’s Guangdong-based RTX 3080 cloud server, paired with a 12-core CPU and 24,576 MB of memory. On paper, it targets developers who need usable GPU performance without stepping into the usual expensive monthly plans.
The goal here is not to walk through AI model deployment in detail, but to look at the basics: how the server is purchased, what the initial environment looks like, and how it performs in simple hardware and network checks.
Buying the server and setting it up
Purchasing
The process starts in the provider’s control panel after registering and signing in. When choosing a cloud server, the selected region is Guangzhou, Guangdong, and the GPU option used for this test is RTX 3080.
Initial environment
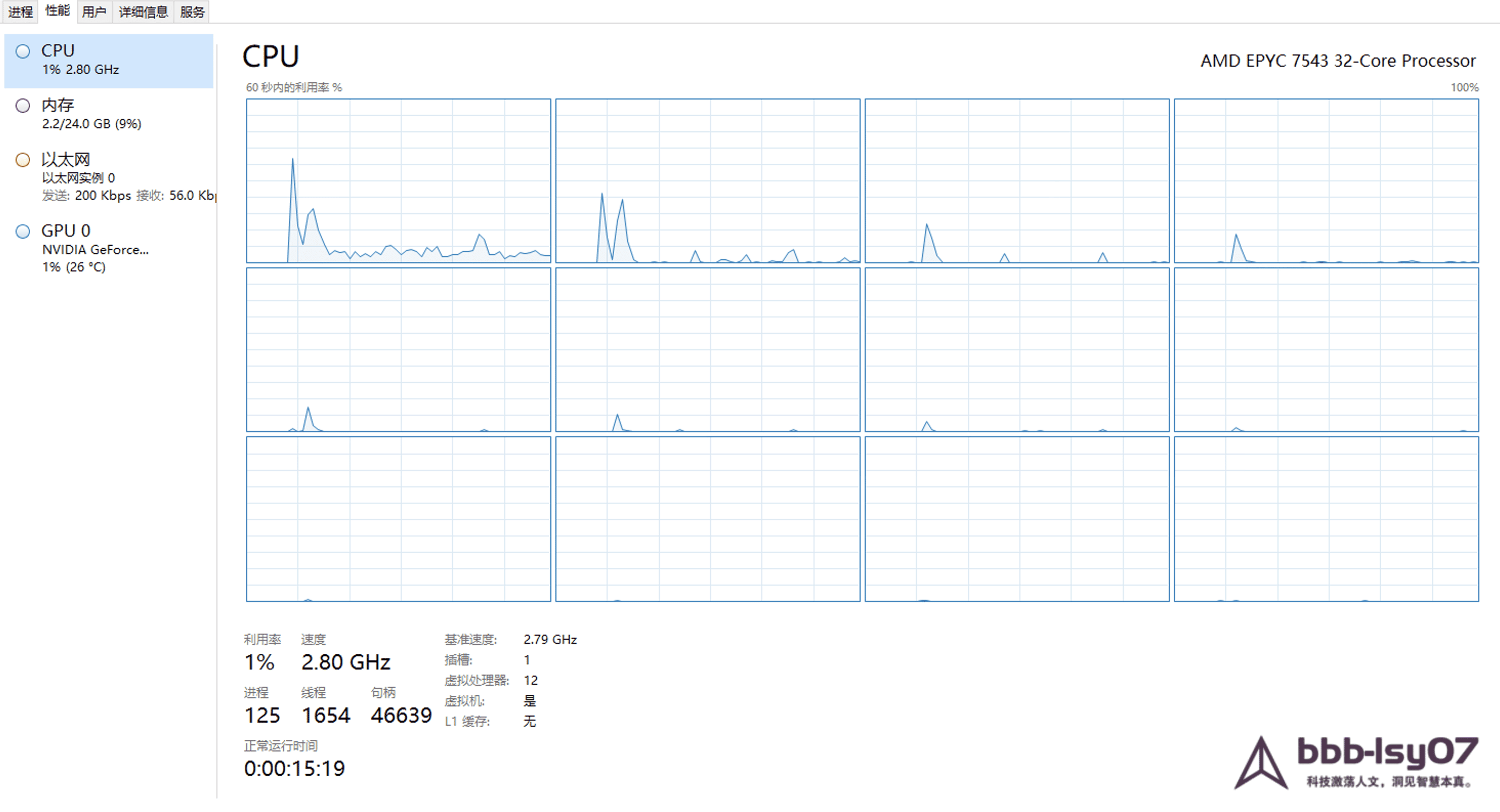
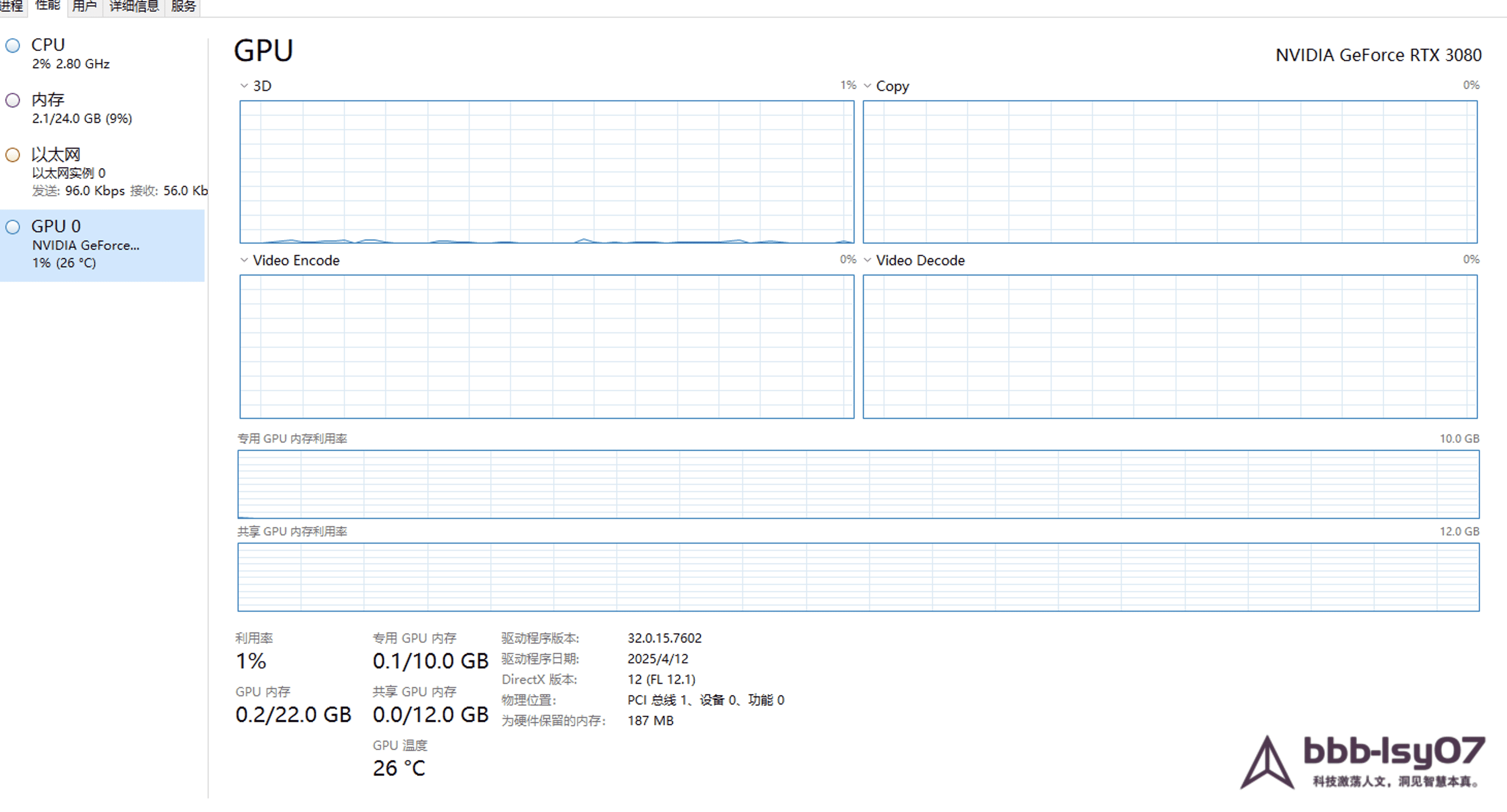
After the instance is created, it can be accessed through remote connection software. Once connected, the system presents the usual basic server information.
For users who prefer a more familiar and manageable server workflow, installing BaoTa Panel can make administration easier.
Installing BaoTa Panel
Inside the control panel for the purchased server, there is an option to reinstall the system or install software. From there, scrolling down to the software installation section allows you to choose the package you want; in this case, BaoTa Panel was selected.
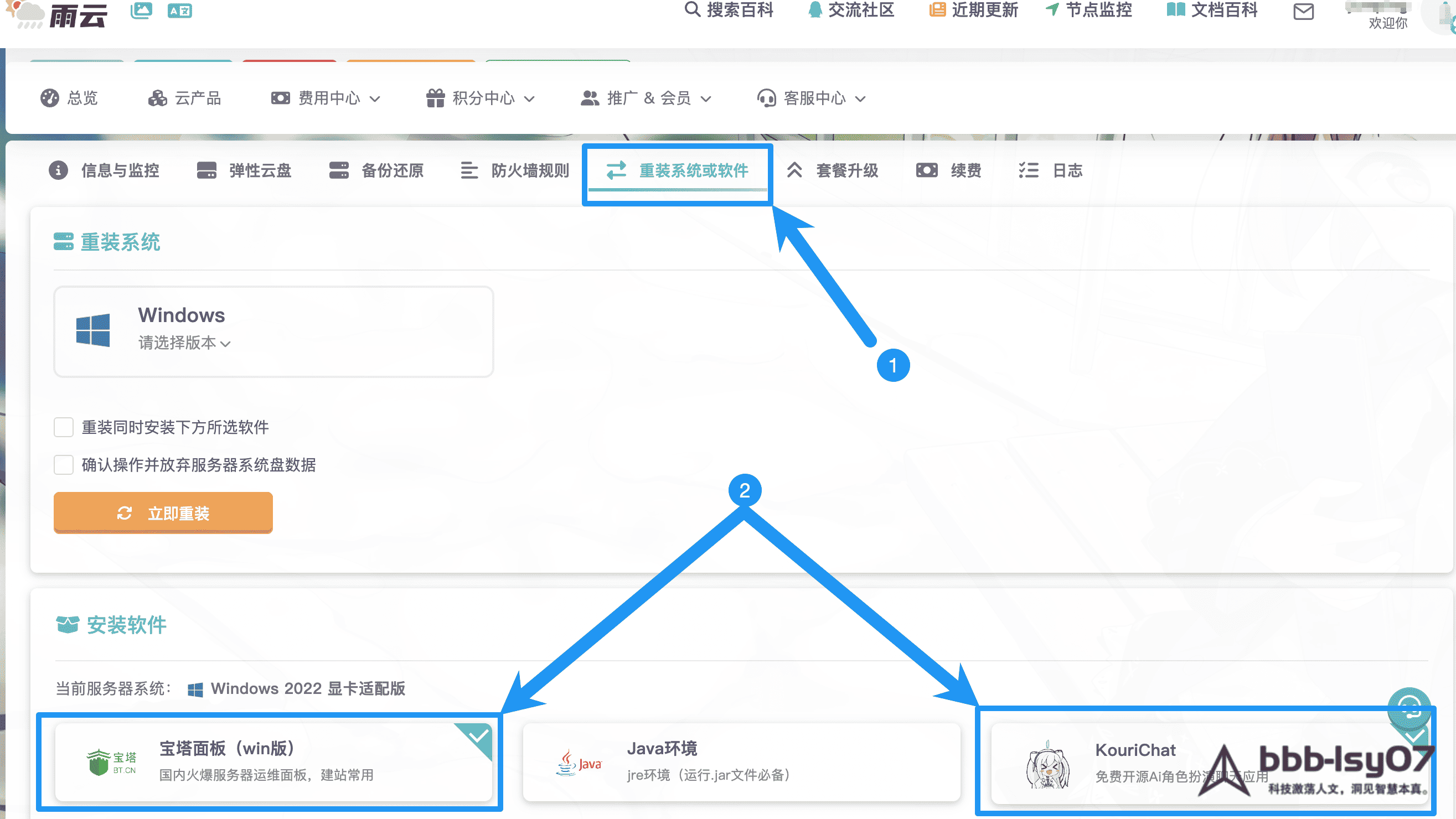
After that, the installer can be found on the remote desktop and launched directly.
Installation completes after a short wait of a few minutes.
Basic performance check
Hardware
To get a quick and broad view of both AI-related capability and general server performance, the test used Lu Master as a reference benchmark. The results are not absolute, but they do give a rough picture of the machine’s level.
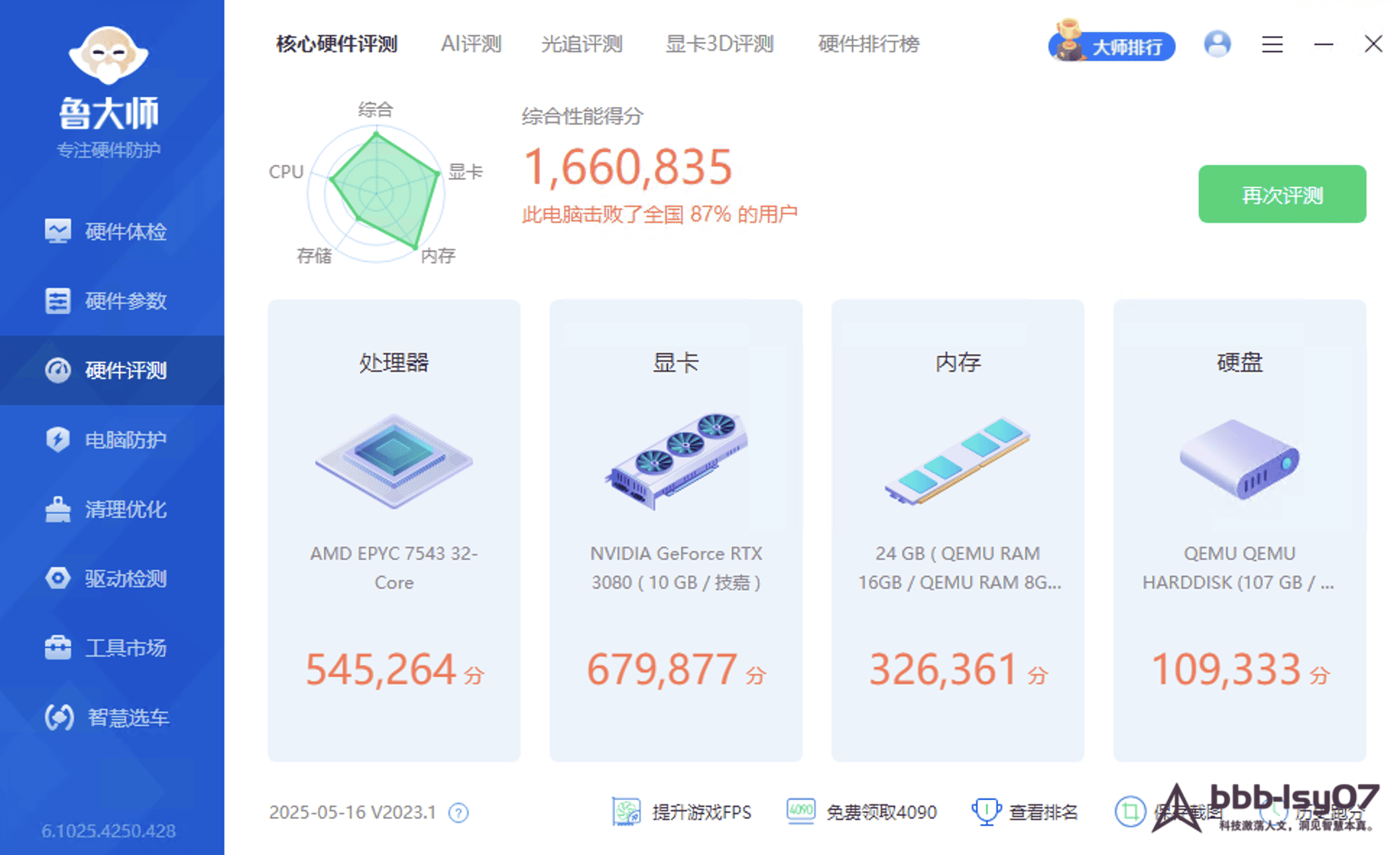
The reported overall performance score was 1,660,835.
Breakdown:
- CPU: 545,264
- GPU: 679,877
- Memory: 326,361
- Storage: 109,333
A separate AI-oriented GPU score was also measured.
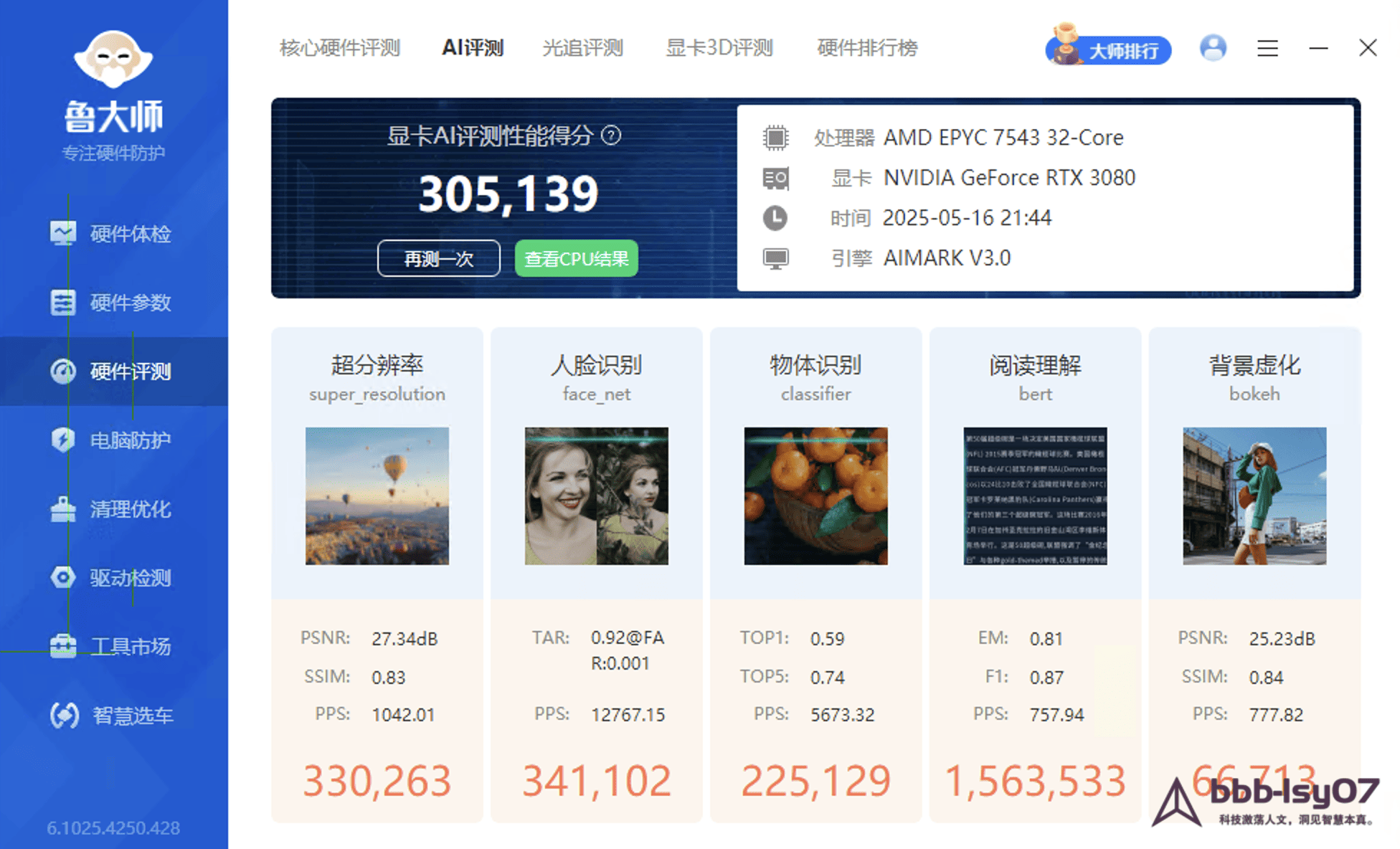
- GPU AI performance score: 305,139
Taken together, the numbers suggest that the RTX 3080 remains very capable for AI workloads. For individual developers or small teams handling mainstream deep learning tasks, it should be suitable for both model training and inference.
Network
Network behavior matters just as much as raw compute for many AI workflows, especially when moving datasets, syncing models, or interacting with remote tools.
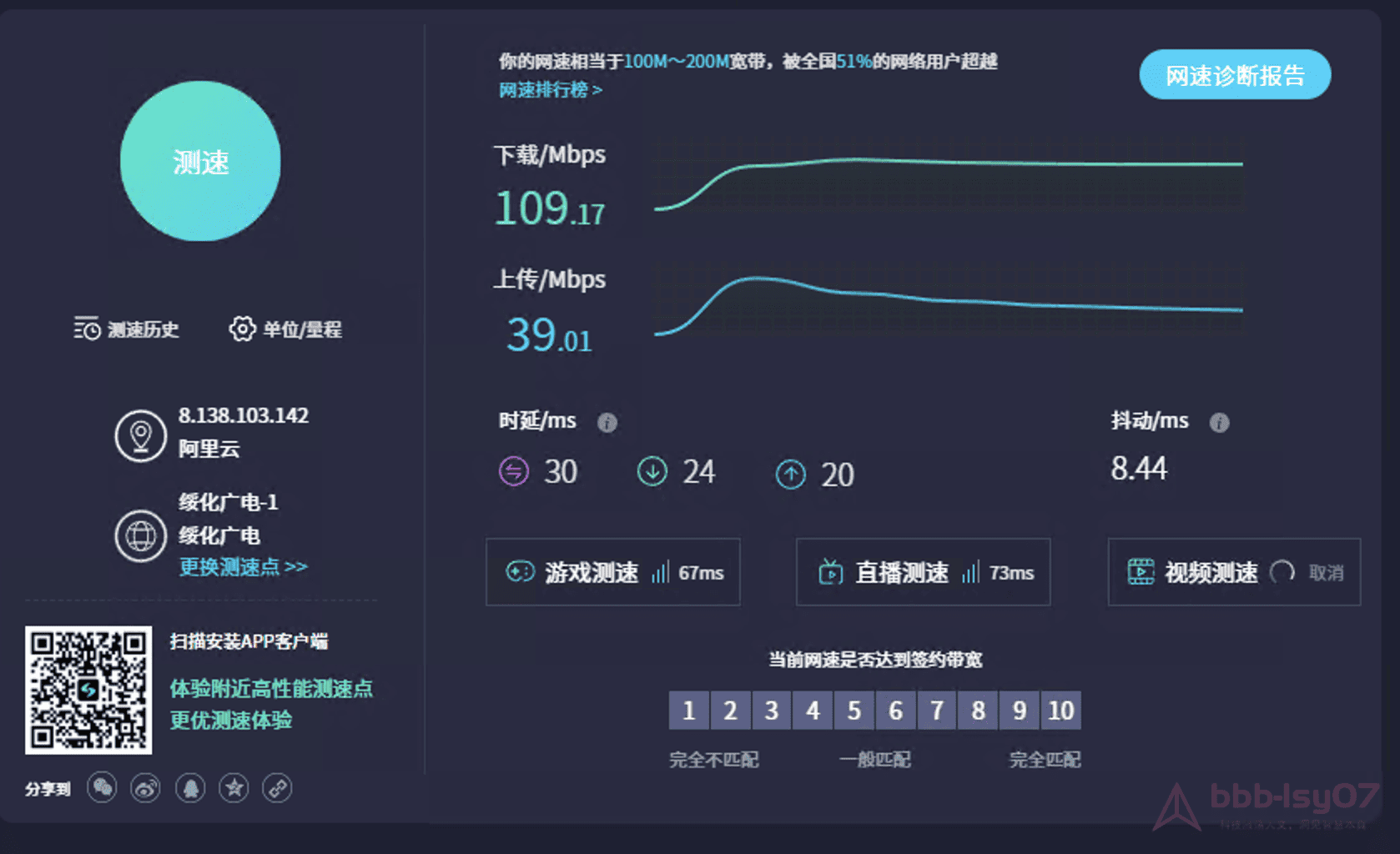
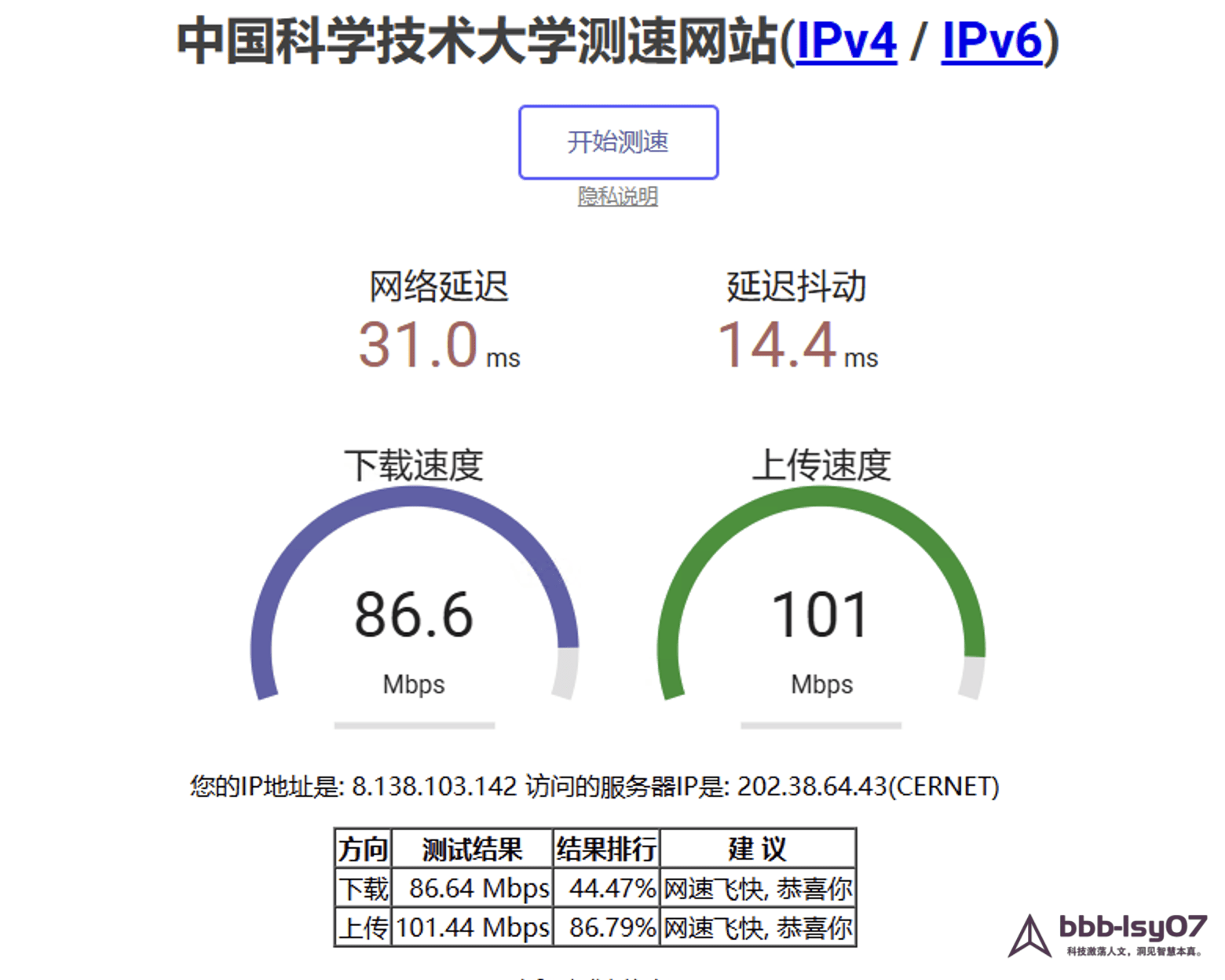
The network tests showed download and upload speeds staying around 100 Mbps during peak periods. That level of bandwidth is enough for ordinary AI development needs, though actual results will still depend on real network conditions and should be treated as reference values rather than guarantees.
What this configuration offers
From a value perspective, this RTX 3080 cloud server stands out because it combines a 12-core CPU, 24 GB of memory, and an RTX 3080 GPU in a package aimed at cost-sensitive users. The measured AI score of 305,139 reinforces that this is not just a nominal GPU offering, but something with practical use for common deep learning workloads.
The network side is also serviceable, with stable 100 Mbps bandwidth helping keep remote development and file transfer reasonably smooth. On top of that, the availability of a management tool like BaoTa Panel lowers the barrier for users who want a more straightforward server administration experience.
Price is the reason this machine gets attention in the first place. The offer discussed here puts the instance at 29 RMB per month, with a 50% discount for the first month, bringing the starting cost to roughly 15 RMB. At that level, it becomes much easier for personal developers to try a dedicated GPU environment without making a heavy financial commitment.
For developers focused on efficient AI experimentation, this kind of server is an appealing middle ground: far cheaper than many traditional GPU cloud options, while still providing enough performance for mainstream model training and inference tasks. It should also have room for broader use cases, including game servers or more complex AI deployments, depending on the workload.